Wie jedes Jahr im Januar beteiligen wir uns an der Wahl zum Anglizismus des Jahres, indem wir die Kandidaten der Endrunde auf ihre Tauglichkeit zum Sieger abklopfen. Bereits abgehandelt haben wir Social Freezing und Phablet, heute ist Big Data an der Reihe.
Das Wort Big Data bezeichnet sowohl Datenmengen, die so groß sind, dass sie mit herkömmlichen Methoden nicht mehr handhabbar sind, als auch die Speicher- und Rechenmethoden, die zur Lösung dieses Problems entwickelt wurden und werden (diese Bedeutungen finden sich im Oxford English Dictionary für das Englische, und unser Jury-Mitglied Michael Mann hat sie im letzten Jahr in seiner Analyse auch für den deutschen Sprachgebrauch gefunden – im Duden steht das Wort noch nicht).
Big Data ist zum zweiten Mal in der Endrunde für den Anglizismus des Jahres, verpasste im letzten Jahr aber deutlich einen vorderen Platz (dafür landete es bei der Wort-des-Jahres-Wahl auf Platz 5). Sehen wir uns an, inwieweit es den Kriterien unseres Wettbewerbs genügt und ob es vielleicht in diesem Jahr ein aussichtsreichen Kandidat für das lexikalische Siegertreppchen ist.
Englische Vorgeschichte
Das Oxford English Dictionary hat seit 2013 einen Eintrag für Big Data und nennt als erste Verwendung eine Passage aus einem Aufsatz des Historikers Charles Tilly von 1980, in der dieser über Versuche spricht, geschichtliche Forschung zu betreiben, in dem „riesige Datenmengen“ (vast quantities of data) mittels komplexer mathematischer Prozeduren (sophisticated mathematical procedures) per Computer (electronic computer) analysiert werden:
Against these procedures, Stone lodges the objections that … none of the big questions has actually yielded to the bludgeoning of the big-data people.
Als die Aufnahme des Wortes 2013 bekanntgegeben wurde, wurden sofort Zweifel laut, dass dies wirklich die erste Verwendung des Wortes im heutigen Sinne sei und auch das Wiktionary schließt Verwendungen vor dem Jahr 2000 kategorisch als Quelle aus und schließt sich der Meinung des Journalisten Steve Lohr an, der den Ursprung der heutigen Bedeutung Mitte in Mittagstisch-Gesprächen der Firma Silicon Graphics in den 1990er Jahren verortet.
Aus meiner Sicht ist diese Diskussion müßig, da Tilly ganz klar von Datenmengen spricht, die (für die damalige Zeit) zu groß für die üblichen Verfahren sind und nur mit speziellen Methoden bearbeitet werden können. Das entspricht der modernen Bedeutung und wenn es keine direkte Tradition von seiner Formulierung zum heutigen Wort gibt, bedeutet das eben, dass das Wort eben mehrfach geschöpft wurde. So ungewöhnlich oder originell ist die Wortschöpfung im Englischen ja auch gar nicht – siehe Wörter wie big pay (1868), big business (1905), big government (1925), big circulation (1929), big science (1948) und big budget (1961).
Auf jeden Fall ist klar, dass big data spätestens seit den frühen 2000er Jahren im Englischen etabliert war. Dabei war übrigens – ich komme später darauf zurück – die Metapher von Daten als Goldmine von Anfang an häufig zu finden, z.B. in dem zweiten vom OED genannten Beleg von 2003: ((Im OED wird dieses Zitat übrigens falsch wiedergegeben – statt „not a pile of dusty tapes“ heißt es dort „not just a collection of dusty tapes“; aber da man mir bisher für meine dort gemeldeten Korrekturen nie auch nur eine automatisierte Dankesmail zurückgeschrieben hat, muss man das dort ohne meine Hilfe merken.))
Much of what is needed is already in place – the collaboration of astronomers and statisticians, the commitment to standards, … and the recognition that big data is a gold mine and not a pile of dusty tapes. [Roy Williams, Grids and the Virtual Observatory]
Entlehnung und weitere Entwicklung
Aus dem Englischen wurde big data dann etwa zehn Jahre später ins Deutsche entlehnt. Der erste echte Treffer im Deutschen Referenzkorpus (DeReKo) stammt aus der Online-Ausgabe der Zeit vom 10. März 2011:
Nach Stuttgart ist der 34-Jährige gekommen, um einen »Bericht zur Lage der Zukunft« vorzutragen. Hinrichs schlendert auf die Bühne, das Hemd hängt an einer Seite aus der Anzughose. Er spricht von der »Cloud«, der Wolke aus Rechnerkapazitäten, die das Internet bildet. Von »Big Data« und »Software as a Service« — riesigen Datenmengen und Programmen, die im Netz »on demand« bereitgestellt werden.
Das bedeutet natürlich nicht, dass das Wort im Deutschen vorher nie verwendet wurde, aber die Treffer im Deutschen Referenzkorpus zeigen, wann das Wort verbreitet und etabliert genug war, um in einem Medium mit einem allgemeinen Adressatenkreis verwendet zu werden. Interessanterweise handelt es sich bei dem Treffer um einen Bericht über einen Vortrag eines Fachmanns; dass es in Anführungszeichen steht, deutet auf die Neuheit und Fremdheit des Wortes zu diesem Zeitpunkt hin.
Wie Michael Mann in seinem Beitrag im letzten Jahr schon festgestellt hat, stammte großer Teil der frühen Treffer aus technischen Quellen (hauptsächlich dem Fachblatt „VDI nachrichten“ des Vereins deutscher Ingenieure): 2011 stammten 80 Prozent aller Treffer aus dieser Quelle oder der Wikipedia, für 2012 stammen noch fast 60 Prozent aus den VDI nachrichten. Im Jahr 2013 stellen Belege aus Tages- und Wochenzeitungen dann aber eine Mehrheit von knapp unter siebzig Prozent, die sich 2014 nicht mehr sehr stark auf knapp über siebzig Prozent steigert. Das zeigt, dass das Wort sich von einem eher fachsprachlichen zu einem allgemeinsprachlichen Wort entwickelt – eine Beobachtung, die auch dadurch gestützt wird, dass der Anteil von Verwendungen des Wortes in Anführungszeichen stetig sinkt. 2011 und 2013 schrieb man in der allgemeinen Presse noch in der Hälfte aller Fälle „Big Data“ statt einfach Big Data, 2013 nur noch in einem Drittel aller Fälle, und 2014 standen dann nur noch knapp 20 Prozent der Verwendungen in Anführungszeichen.
Was die allgemeine Häufigkeitsentwicklung betrifft, so stellt 2014 den bislang höchsten Stand der Verwendungshäufigkeiten im DeReKo und dem Suchinteresse bei Google Trends dar, wie die folgende Grafik zeigt (für beide Datenreihen habe ich die größte jährliche Häufigkeit als 100 Prozent gesetzt und die übrigen Jahre relativ zu dieser Summe berechnet, die DeReKo-Daten habe ich vorher noch auf Treffer pro einer Million Wörter normalisiert).
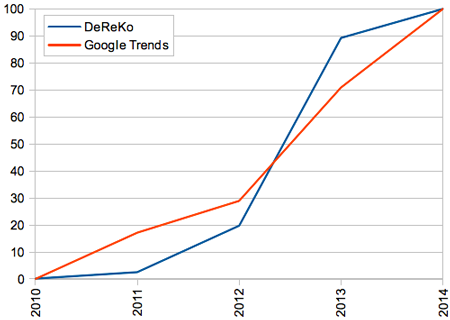
Häufigkeitsentwicklung des Wortes Big Data im Deutschen Referenzkorpus und bei Google Trends
Das Wort ist also ganz klar dabei, zu einem selbstverständlichen Teil des deutschen Wortschatzes zu werden. Sogar die Bundeskanzlerin, aus informationstechnischer Perspektive vor allem dafür berüchtigt, das Internet mehr als ein Vierteljahrhundert nach seiner Erfindung und zu einem Zeitpunkt, da über drei Viertel der deutschen Bevölkerung online sind, als „Neuland“ zu bezeichnen, erkannte 2014 die besondere Relevanz des Begriffs. In ihrer Rede anlässlich des 8. Nationalen IT-Gipfels am 21. Oktober 2014, in dem sie auch „Frequenzen, Förderung und Festnetz“ zu den „drei F“ der deutschen IT-Politik erklärte sie:
…dass wir unseren deutschen Datenschutz nicht zur Disposition stellen wollen. […] Auf der anderen Seite müssen wir dafür sorgen, dass das Management von Big Data möglich ist. Wenn ich höre, dass man schon von „Big Data Mining“ spricht, dann erinnert mich das natürlich an den deutschen Steinkohlebergbau. Aber es könnte sein, dass das ganze Unternehmen doch gewinnträchtiger ist.
Damit greift sie (bzw. ihr/e Redenschreiber/in) die Bergbaumetapher auf, die mit dem Wort Big Data auch im Englischen so eng verknüpft ist. Dass sie dabei als Vergleichsmaßstab anstatt der Goldmine des englischen Sprachgebrauchs die Steinkohle wählt, könnte man als bodenständig-deutschen Realismus werten, wenn es nicht andernorts im selben Jahr schon Pläne gegeben hätte, die Deutschen zu Weltmeistern beim Schürfen von Big Data zu machen (Big reicht dabei dann auch nicht mehr, es sollen Smart Data werden).
Fazit
Big Data ist ein solider Kandidat. Das Wort besteht aus englischem Sprachmaterial und wurde aus dem Englischen ins Deutsche entlehnt. Dort füllt es eine Lücke, die sich durch eine neue technische Entwicklung im deutschen Wortschatz aufgetan hat, und für die nicht einmal die notorisch wortschöpferische Wikipedia bisher eine deutsche Alternative vorschlägt. Das Wort hat einen Häufigkeitsanstieg hinter sich, in dessen Verlauf es sich von fachsprachlichen in allgemeinsprachliche Zusammenhänge vorgearbeitet hat. Vorwerfen könnte man dem Wort höchstens, dass der Häufigkeitsanstieg zwischen 2012 und 2013 drastisch war, zwischen 2013 und 2014 dann aber nur noch minimal – es hätte seine Chance also eher im letzten Jahr gehabt. Dass es im letzten Jahr nicht einmal in die Top 5 kam, dürfte daran liegen, dass es weder die Jury noch die Allgemeinheit bei der Publikumsabstimmung besonders inspiriert hat. Ja, es füllte auch 2013 schon eine Lücke, aber eine Lücke, für die sich auf gesellschaftlicher Ebene (noch?) keine rechte Leidenschaft entzündet hatte. Ob das in diesem Jahr anders ist, vielleicht durch die semantische Verknüpfung mit der allseits beliebten Tradition des Steinkohlebergbaus, wird sich zeigen.
Vielen Dank für die ausführliche Betrachtung! Als kleine Randnotiz: Der VDI ist der Verein deutscher Ingenieure (und Herausgeber der “vdi nachrichten”). Die Industrie ist im Bundesverband der Deutschen Industrie (BDI) organisiert.
Danke, ich habe das korrigiert! A.S.
Pingback: Kandidaten für den Anglizismus 2014: Big Data | ANGLIZISMUS DES JAHRES
Ist Big Data wirklich ein rein technischer Begriff? Mir fehlt hier irgendwie die für mich ganz klar negative Konnotation. Big Data heißt für mich, dass man — in dem Fall Akteure wie soziale Netzwerke, Internethändler, Geheimdienste — nicht mehr entscheiden muss, was man speichert, man speichert einfach alles und wirft dann ausgeklügelte Algorithmen darauf, die aus diesem Datenbrei Kommunikations‑, Bewegungs‑, Verhaltens- und letztlich Persönlichkeitsprofile extrahieren können.
Danke für das Merkel-Zitat übrigens. Data Mining mit Steinkohle in Verbindung zu bringen ist dermaßen bizarr, das schlägt das Neuland nochmal um Längen 🙂
Eine kleine Randnotiz, da ich gerade in einen Vortrag von Sandy Pentland mit dem Titel “Social Physics” reingelaufen bin: Die Leute vom MIT bezeichnen den Methodenteil von Big Data mit Social Physics (ich habe nichts Physikalisches daran erkennen können). Ich habe aber den Eindruck, dass das ein dort erfundener Ausdruck ist, der außerhalb des MIT nicht groß gebraucht wird.